Uwsgi multihosting s monitoringom cez grafana
Nastavenie webového servera pre python aplikácie môže byť celkom náročná úloha hlavne kvôli nedostatku dostatočne komplexných návodov. V tomto článku skúsim vysvetliť ako ja nastavujem servery.
Ako server som zvolil Ubuntu Server 23.10. Postup by mal s malými zmenami fungovať prakticky na ľubovoľnej distribúcii založenej na Debian Linuxe. Všetky príkazy budú vykonávané ak to nebude uvedené inak pod používateľom root. V príkazoch preto nebudem uvádzať sudo a budem predpokladať, že používateľ je priamo prihlásený ako root (napríklad príkazom sudo su).
Vytváranie používateľov a adresárovej štruktúry
Na serveri bude niekoľko projektov a potenciálne aj niekoľko používateľov. Preto som navrhol nasledujúci spôsob správy používateľov a ich adresárov:
- Každý web má vlastného používateľa (bez možnosti prihlásenia)
- Každý web (synonymum pre názov socketu a meno používateľa) je priradený v skupine
www-dataa v skupine klienta (jeden klient môže mať viacej webov) - Používatelia majú svoje domovské adresáre v
/var/www/clients/<skupina>/<používateľ> - Každý používateľ má meno podľa hlavnej domény webu (napríklad pre
linuxos.skby sa volallinuxos.ska mal by svoju skupinulinuxos-team,www-data) - Používateľský adresár má odkaz do
/var/wwwnapríklad/var/www/linuxos.sk
Pre stránku linuxos.sk by išlo o nasledujúce príkazy:
# vytvorenie skupiny groupadd linuxos-team # vytvorenie užívateľského adresára (s jedným podadresárom web) mkdir -p /var/www/clients/linuxos-team/linuxos.sk/web # zmena práv pre home adresár chown linuxos.sk:linuxos-team /var/www/clients/linuxos-team/linuxos.sk/ # pridanie používateľa bez možnosti prihlásenia useradd -d /var/www/clients/linuxos-team/linuxos.sk -g linuxos-team -M -s /bin/false linuxos.sk # pridanie používateľa do skupiny www-data usermod -a -G www-data linuxos.sk # vytvorenie odkazu ln -s /var/www/clients/linuxos-team/linuxos.sk /var/www/linuxos.sk
Keďže proces pridávania používateľov je vážne nudný a repetitívny a my programátori neradi robíme tie isté veci stále a stále znovu nehovoriac o vyhľadávaní návodu, pripravil som si bash skript, ktorý túto úlohu vyrieši za mňa. Povedzme, že nasledujúci skript si pomenujem web_user_add:
#!/bin/bash # Nápoveda if [ "$#" -ne 3 ]; then echo "web_add host system_user system_group" exit -1 fi host=$1 sys_user=$2 sys_group=$3 # Nie je vytvorená skupina? Vytvoríme if [[ ! $(getent group $sys_group) ]]; then groupadd $sys_group usermod -a -G $sys_group www-data fi # Nie je vytvorený používateľ? Vytvoríme if [[ ! $(getent passwd $sys_user) ]]; then mkdir -p /var/www/clients/$sys_group/$sys_user/web chown $sys_user:$sys_group -R /var/www/clients/$sys_group/$sys_user useradd -d /var/www/clients/$sys_group/$sys_user -g $sys_group -M -s /bin/false $sys_user usermod -a -G www-data $sys_user fi # Vytvorenie odkazu ln -s /var/www/clients/$sys_group/$sys_user /var/www/$host
Teraz už stačí len spustiť ./web_user_add linuxos.sk linuxos.sk linuxos-team.
Uwsgi server
Zvyčajne prevádzkujem klasické Web Server Gateway Interface aplikácie. Existuje množstvo čistých wsgi, alebo kombinovaných asgi / wsgi serverov. Ja konkrétne používam uWSGI, čo je dnes považované už prakticky za neudržiavanú vykopávku. Má však veľmi zaujímavé vlastnosti, ktoré som v iných serveroch nenašiel, napríklad podporu socketovej aktivácie, automatické škálovanie, monitoring, routing, plánovanie úloh na pozadí atď.
Najjednoduchšou voľbou, ako začať s multi-app prevádzkou je uWSGI Emperor. Tento režim umožňuje spravovať niekoľko aplikácii súbežne. Zároveň zvláda automatické spúšťanie nových workerov pri záťaži, či naopak ich vypínanie v prípade, že už nie sú potrební. Ako čerešničku na torte by som spomenul možnosť cheap, pri ktorej sa len vytvorí socket a prvý worker sa spustí až pri požiadavke.
Dosť bolo marketingového blábolu, nastal čas vyhrnúť si rukávy a konfigurovať. Upozorňujem, že táto časť nie je nič pre slabšie povahy a bude zahŕňať pomerne pokročilé techniky, na ktoré autor prišiel pri všetkej skromnosti sám a stálo ho to nemalé úsilie.
Začnem inštaláciou uwsgi serveru, ktorá je na distribúciach založených na debiane veľmi jednoduchá - apt install uwsgi-plugin-python3.
Konfiguráciu začnem prvým a hlavným konfiguračným súborom pre uwsgi emperor - /etc/uwsgi/emperor.ini. Súbor odkazuje na ďalšie konfiguračné súbory a nástroje, ktoré si postupne prejdeme. Tu je už sľúbená konfigurácia:
[uwsgi] plugin = syslog logger = syslog:emperor master-fifo = /run/uwsgi/emperor.fifo emperor = /etc/uwsgi/apps-enabled emperor-stats = /run/uwsgi/emperor-stats.sock emperor-on-demand-exec = /etc/uwsgi/make_rundir.py vassals-inherit = /etc/uwsgi/default-inherit.ini vassals-include-before = /etc/uwsgi/default-include-before.ini #emperor-tyrant = true #cap = setgid,setuid
Prvé 2 direktívy zapínajú logovanie do syslogu pod identifikátorom emperor. Pomocou tohto identifikátora bude neskôr možné identifikovať logy pochádzajúce z hlavného procesu. Ak je logovanie nastavené správne, výsledné logy vyzerajú približne takto:
Sat Nov 18 13:13:19 2023 - [emperor] vassal linuxos.sk.ini is ready to accept requests Sat Nov 18 13:13:21 2023 - [emperor] vassal linuxos.sk.ini is now loyal
Direktíva master-fifo nastavuje cestu k rúre pre ovládanie. Do rúry je možné posielať príkazy definované v dokumentácii. Osobne som z týchto možností nevyužil ešte reálne nič okrem preskenovania konfigurácie (echo "E" > /run/uwsgi/emperor.fifo).
Pod direktívou emperor sa skrýva cesta ku konfigurácii k jednotlivým webom (vassals). V tomto prípade je to adresár s konfiguračnými súbormi, ale môže tu byť aj napríklad konfigurácia z postgresql databázy. Podrobnejšie informácie sa nachádzajú v dokumentácii.
Štatistiky o jednotlivých weboch a procesoch sa dajú exportovať cez direktívu emperor-stats.
Pod podozrivou direktívou emperor-on-demand-exec sa dokonca skrýva cesta k skriptu. K jeho úlohe sa vrátim v časti o spúšťaní on-demand.
Nasledujúce direktívy vassals-inherit a vassals-include-before definujú spoločnú konfiguráciu pre všetky weby. Stále platí, že som lenivý programátor, ktorému sa nechce všetko konfigurovať pre každý web. Prečo sú však direktívy 2?
Existujú 2 direktívy pre vloženie spoločnej konfigurácie inherit a include. Okrem toho existujú ešte v 2 variantoch a to príponou -before kedy sú akoby vložené na začiatok konfiguračného súboru a bez prípony, kedy sú na konci. Rozdiel medzi inherit a include spočíva v expanzii environment premenných a v tomto prípade rozdiel nie je dôležitý. Čo je však dôležité je prípona -before, bez ktorej by nebolo možné "prebiť" globálne nastavenia špecifickými nastaveniami v konfigurácii konkrétneho webu. Podrobnosti o spôsobe spracovania konfiguračného súboru sú v dokumentácii.
Paranoidní používatelia môžu využiť režim emperor-tyrant, pri ktorom weby rovno štartujú s obmedzenými právami. V bežnom režime naopak štartujú s právami, ktoré má emperor a na základe konfigurácie svoje práva degradujú (ešte v čase pred spustením kódu používateľa).
Globálne nastavenia webov
Súbor default-inherit.ini bude obsahovať všetky nastavenia, ktoré nebude možné prepísať v konfiguračných súboroch jednotlivých webov.
[uwsgi] plugin = syslog logger = syslog:%N logformat = %(method) %(status) %(msecs)ms %(size)b %(uri) master = 1 # limit pre beh skriptu harakiri = 60 harakiri-verbose = 1 # automatické vypnutie procesu cheap = true idle = 3600 die-on-idle = true # nastavenie ciest chdir = /var/www/%N/web/app pythonpath = /var/www/%N/web/app virtualenv = /var/www/%N/web/virtualenv # python modul module = wsgi chmod-socket = 660 stats = /run/uwsgi/stats/%N.sock memory-report = true safe-pidfile = /run/uwsgi/apps/%N/pid #cgroup = /sys/fs/cgroup/cpu/uwsgi/%N #cgroup = /sys/fs/cgroup/memory/uwsgi/%N #cgroup-opt = memory.limit_in_bytes = 6442450944
Na začiatku súboru je opäť nastavenie logov. Magická premenná %N obsahuje názov hlavného konfiguračného súboru bez prípony. Konfiguračný súbor webu bude mať názov linuxos.sk.ini, takže táto magická premenná bude obsahovať linuxos.sk. Syslog identifikátor bude preto obsahovať názov domény linuxos.sk, čo nám umožní filtrovať logy podľa konkrétneho webu.
Direktíva master určuje spôsob vytvorenia procesu. V zásade platí, že procesy webu by mali mať nastavenú direktívu master a emperor nie.
Pomocou direktívy harakiri sa nastavuje čas, po ktorom sa zabije worker ak nebude odpovedať.
Nasledujúca časť s direktívami cheap, idle a die-on-idle povoľuje aktiváciu socketom a časovač, ktorý vypne inštanciu, ak po zvolenú dobu nebude prijatá žiada požiadavka.
Ďalej tu máme konfiguráciu ciest, v ktorej sú použité magické premenné. Hodnota %N sa nahradí názvom hlavného konfiguračného súboru bez prípony.
Pomocou direktívy module sa nastavuje python modul, ktorý bude obsahovať entry point aplikácie (funkciu application).
Vytvorený socket má mať práva 660, teda plný prístup pre používateľa a skupinu.
Každý projekt bude mať vlastný socket určený direktívou stats, cez ktorý sa dajú čítať štatistiky. Direktívou memory-report sa zapína export informácií o obsadenej pamäti do štatistík.
Nakoniec zostáva už len nastavenie PID súboru.
Ak používate cgroups v1, je možné nastaviť limity priamo pre worker. Žiaľ podpora v2 v dobe písania nie je implementovaná.
V súbore default-include-before.ini budú direktívy, ktoré sa môžu môžu v nastaveniach jednotlivých webov prepísať.
[uwsgi] processes = 4 cheaper = 1 cheaper-initial = 1 cheaper-step = 1 uid = www-data gid = www-data chown-socket = www-data:www-data
V tomto súbore nastavujem najskôr počet workerov. Webová aplikácia si v tomto prípade môže spustiť maximálne 4 procesy.
Ďalej nasleduje nastavenie automatického škálovania pomocou direktív cheaper. Škálovanie sa začína na 1 procese a počet procesov sa zvyšuje / znižuje po 1 procese.
Nakoniec sa nastavuje používateľ / skupina procesu a práva pre socket.
Spustenie on demand
Pri inicializácii on-demand inštancie môže uwsgi emperor spustiť ľubovoľný skript. Účelom skriptu je príprava prostredia pre beh webu. Môže napríklad vytvárať potrebné adresáre. Nakoniec musí vrátiť cestu k unix socket súboru. Takto konkrétne vyzerá môj /etc/uwsgi/make_rundir.py:
#!/usr/bin/env python3 import configparser import grp import os import pwd import socket import sys # uwsgi posiela názov konfiguračného úboru ako args[1] confname = sys.argv[1] basename = os.path.basename(confname) appname = os.path.splitext(basename)[0] # načítanie konfigurácie config = configparser.ConfigParser(strict=False) config.read(confname) # vytvorenie adresára so štatistikami dirname = '/run/uwsgi/stats/' try: os.makedirs(dirname) except OSError: pass uid = pwd.getpwnam('www-data').pw_uid gid = grp.getgrnam('www-data').gr_gid os.chown(dirname, uid, gid) os.chmod(dirname, 504) # 770 # vytvorenie socketu pre štatistiky stats_socket_file = f'/run/uwsgi/stats/{appname}.sock' try: os.unlink(stats_socket_file) except OSError: pass sock = socket.socket(socket.AF_UNIX, socket.SOCK_STREAM) sock.bind(stats_socket_file) # vytvorenie /run/uwsgi/apps dirname = '/run/uwsgi/apps/%s' % appname try: os.makedirs(dirname) except OSError: pass # načítanie uid / gid zo súboru config = dict(config.items('uwsgi')) config.setdefault('uid', 'www-data') config.setdefault('gid', 'www-data') # nastavenie práv uid = pwd.getpwnam(config['uid']).pw_uid gid = grp.getgrnam(config['gid']).gr_gid perms = '%s:%s' % (config['uid'], config['gid']) if uid == 0 or gid == 0: sys.stderr.write("Dangerous") sys.exit(-1) os.chown(dirname, uid, gid) os.chmod(dirname, 504) # 770 os.chown(stats_socket_file, uid, gid) os.chmod(stats_socket_file, 432) # 660 # vrátenie cesty k socketu sys.stdout.write('%s/socket' % dirname)
Konfigurácia webovej aplikácie
Konfiguráciu webových aplikácií umiestňujem štandardne do adresára /etc/uwsgi/apps-available. V adresári /etc/uwsgi/apps-enabled sú symbolické odkazy na súbory v apps-available, čo umožňuje jednoducho zapínať / vypínať weby vytvorením či zmazaním odkazu.
Kompletná konfigurácia linuxos.sk.ini môže vyzerať napríklad takto:
[uwsgi] plugins = python3 processes = 8 uid = linuxos.sk gid = linuxos-team chown-socket = linuxos.sk:linuxos-team
Webová aplikácia
Teraz si v adresári /var/www/linuxos.sk/web vytvoríme ukážkovú aplikáciu.
Najskôr v adresári vytvoríme python virtualenv prostredie príkazom python3 -m venv virtualenv. Aplikácia bude umiestnená v podadresári app ako súbor wsgi.py. Kompletný súbor vyzerá takto:
def application(env, start_response): start_response('200 OK', [('Content-Type','text/html')]) return [b"Hello World"]
Spustenie systémovej služby
Na dokončenie konfigurácie zostáva jediná drobnosť - vytvorenie systémovej služby pre spustenie uwsgi. V adresári /etc/systemd/system vytvoríme súbor emperor.uwsgi.service.
[Unit] Description=uWSGI Emperor After=syslog.target [Service] ExecStartPre=/bin/mkdir -p /run/uwsgi ExecStart=/usr/bin/uwsgi --ini /etc/uwsgi/emperor.ini ExecReload=/bin/echo "E" > /run/uwsgi/emperor.fifo Restart=always KillSignal=SIGQUIT Type=notify NotifyAccess=all [Install] WantedBy=multi-user.target
Tu sa nastavujú príkazy pre vytvorenie pracovného adresára, spustenie daemona, alebo načítanie adresára s konfiguračnými súbormi poslaním písmena E do riadiacej rúry /run/uwsgi/emperor.fifo.
Služba sa následne naštartuje príkazom systemctl start emperor.uwsgi.service.
Logy sa dajú sledovať príkazom journalctl -f -u emperor.uwsgi.service. Je možné filtrovať logy podľa jednotlivých identifikátorov, napríklad journalctl -f -u emperor.uwsgi.service SYSLOG_IDENTIFIER=emperor pre sledovanie hlavného procesu, alebo SYSLOG_IDENTIFIER=linuxos.sk pre sledovanie logov pre konkrétny web.
Webový server nginx
Inštaláciu webového servara opäť vykonáme klasickým debianovským spôsobom: apt install nginx-full.
Konfiguráciu začnem nastavením formátu logov v hlavnom konfiguračnom súbore /etc/nginx/nginx.conf. Do sekcie http pridávam nastavenia formátu logov, ktoré sa budú jednoducho strojovo čítať:
log_format syslog_format '$request_method $status $request_time(ms) $bytes_sent(B) upstream[response=$upstream_response_time(ms) ttfb=$upstream_header_time(ms)] $remote_addr $request_uri $http_user_agent';
Konfigurácia webu linxuos.sk bude opäť uložená tak, aby sa dala ľahko zapínať / vypínať. Kompletná konfigurácia /etc/nginx/sites-available/linuxos.sk.conf vyzerá takto:
server {
listen 80;
listen [::]:80;
server_name linuxos.sk;
access_log syslog:server=unix:/dev/log,facility=local7,tag=linuxos_sk,severity=info syslog_format;
location / {
include uwsgi_params;
uwsgi_pass unix:///run/uwsgi/apps/linuxos.sk/socket;
}
}
Tento súbor v podstate len hovorí, že má počúvať na adrese linuxos.sk, porte 80 a posielať všetky požiadavky serveru uwsgi. Prístupové logy sú odosielané do syslogu pod značkou linuxos_sk. Špeciálne znaky ako napríklad bodka nie sú povolené.
Aby bolo možné webovú stránku načítať, je potrebné ešte pridať adresu linuxos.sk do /etc/hosts.
127.0.1.1 linuxos.sk ::1 linuxos.sk
Po vytvorení odkazu v sites-enabled a reloade servera systemctl reload nginx je možné načítať web:
curl http://linuxos.sk/ Hello World
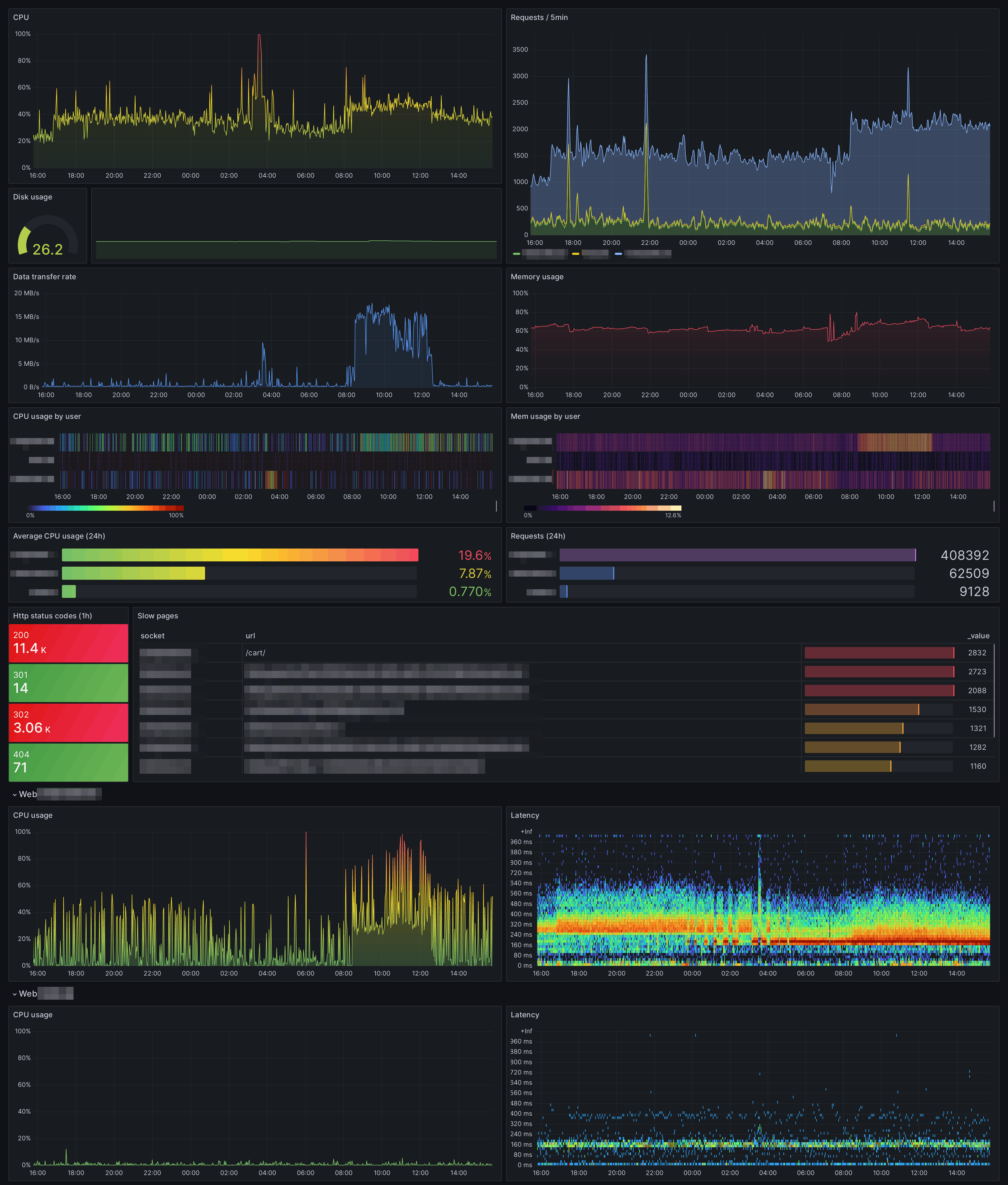
Telemetria
Za dôležitú časť starostlivosti o multihosting považujem monitoring zdrojov. Mať prehľad o rezervách vo výkone, či o nepokrytých špičkách, alebo neposlušných robotoch, ktoré nechtiac robia na server DDoS útok môže byť celkom užitočné.
Architektúra
Monitoring bude založený na 3 samostatných navzájom zameniteľných komponentoch:
- Zber údajov
- Nástroj telegraf je excelentným zberačom údajov. Vie získavať informácie o systéme z rôznych rôznych konfigurovateľných zdrojov. Následne je schopný pozbierané údaje posielať do rôznych databáz, alebo súborov. Typicky každý server má spustenú vlastnú inštanciu telegrafu, ktorá buď aktívne zasiela údaje v pravidelných intervaloch, alebo počúva na vybranom porte a v prípade požiadavky odpovie aktuálnymi nameranými hodnotami.
- Zaznamenávanie údajov (databáza)
- Telemetrické údaje sa najlepšie zaznamenávajú do špeciálne na to určenej databázy. Na výber je napríklad Prometheus, ale vzhľadom na to, že zaznamenávam aj niektoré textové údaje som nakoniec skončil pri použití InfluxDB. Databáza zvyčajne beží na jednom stroji ak nie je nevyhnutné škálovanie kvôli výkonu, alebo väčšia odolnosť voči výpadkom.
- Vizualizácia a upozornenia
- V oblasti vizualizácie zase exceluje nástroj Grafana, ktorý vie čítať a zobrazovať dáta z rôznych databáz.
Inštalácia a nastavenie databázy InfluxDB 2.x
Keďže telegraf aj grafana sú závislé na databáze, bude najrozumnejšie začať práve inštaláciou databázy.
Podľa stránky s okazmi na stiahnutie je postup inštalácie pre Debian / Ubuntu nasledovný:
wget -q https://repos.influxdata.com/influxdata-archive_compat.key echo '393e8779c89ac8d958f81f942f9ad7fb82a25e133faddaf92e15b16e6ac9ce4c influxdata-archive_compat.key' | sha256sum -c && cat influxdata-archive_compat.key | gpg --dearmor | tee /etc/apt/trusted.gpg.d/influxdata-archive_compat.gpg > /dev/null echo 'deb [signed-by=/etc/apt/trusted.gpg.d/influxdata-archive_compat.gpg] https://repos.influxdata.com/debian stable main' | sudo tee /etc/apt/sources.list.d/influxdata.list apt-get update && apt install influxdb2
Po úspešnej inštalácii je možné databázu naštartovať príkazom systemctl start influxdb. Nasledovať by mala konfigurácia, pri ktorej sa vytvoria prístupové údaje. Ja som pre všetky polia vyplnil telegraf, pretože som vážne lenivý a službu používam len v lokálnej sieti.
# influx setup > Welcome to InfluxDB 2.0! ? Please type your primary username telegraf ? Please type your password ******** ? Please type your password again ******** ? Please type your primary organization name telegraf ? Please type your primary bucket name telegraf ? Please type your retention period in hours, or 0 for infinite 72 ? Setup with these parameters? Username: telegraf Organization: telegraf Bucket: telegraf Retention Period: 72h0m0s Yes User Organization Bucket telegraf telegraf telegraf
Pre autentifikáciu bude vyžadovaný token, ktorý je možné zistiť príkazom influx auth list:
ID Description Token User Name User ID Permissions 0c262a48f390a000 telegraf's Token _IQwe0LFcZgILzW-Blre9E9s80FUCo8SgU0lrxAZB-BPFg-HGJvd0zqEMXfL8-YcBR7olvMppvCyQY8_YX6izg== telegraf 0c262a48de90a000 [read:/authorizations write:/authorizations read:/buckets write:/buckets read:/dashboards write:/dashboards read:/orgs write:/orgs read:/sources write:/sources read:/tasks write:/tasks read:/telegrafs write:/telegrafs read:/users write:/users read:/variables write:/variables read:/scrapers write:/scrapers read:/secrets write:/secrets read:/labels write:/labels read:/views write:/views read:/documents write:/documents read:/notificationRules write:/notificationRules read:/notificationEndpoints write:/notificationEndpoints read:/checks write:/checks read:/dbrp write:/dbrp read:/notebooks write:/notebooks read:/annotations write:/annotations read:/remotes write:/remotes read:/replications write:/replications]
Inštalácia a nastavenie telegrafu
Návod na inštaláciu pre Ubuntu / Debian sa prakticky nelíši od od InfluxDB a pozostáva z pridania repozitára a inštaláciu cez apt:
wget -q https://repos.influxdata.com/influxdata-archive_compat.key echo '393e8779c89ac8d958f81f942f9ad7fb82a25e133faddaf92e15b16e6ac9ce4c influxdata-archive_compat.key' | sha256sum -c && cat influxdata-archive_compat.key | gpg --dearmor | tee /etc/apt/trusted.gpg.d/influxdata-archive_compat.gpg > /dev/null echo 'deb [signed-by=/etc/apt/trusted.gpg.d/influxdata-archive_compat.gpg] https://repos.influxdata.com/debian stable main' | tee /etc/apt/sources.list.d/influxdata.list apt-get update && apt install telegraf
Minimálna konfigurácia
Zatiaľ budem ignorovať štandardný a začnem úplne jednoduchým čistým konfiguračným súborom telegraf.conf:
[[outputs.file]] files = ["/tmp/telegraf.out"] [[inputs.mem]]
Po spustení telegraf --config telegraf.conf --debug sa v konzole zobrazí výpis podobný tomuto:
2023-11-25T16:09:09Z I! Starting Telegraf 1.22.3+ds1-0ubuntu2 2023-11-25T16:09:09Z I! Loaded inputs: mem 2023-11-25T16:09:09Z I! Loaded aggregators: 2023-11-25T16:09:09Z I! Loaded processors: 2023-11-25T16:09:09Z I! Loaded outputs: file 2023-11-25T16:09:09Z I! Tags enabled: host=linuxos 2023-11-25T16:09:09Z I! [agent] Config: Interval:10s, Quiet:false, Hostname:"linuxos", Flush Interval:10s 2023-11-25T16:09:09Z D! [agent] Initializing plugins 2023-11-25T16:09:09Z D! [agent] Connecting outputs 2023-11-25T16:09:09Z D! [agent] Attempting connection to [outputs.file] 2023-11-25T16:09:09Z D! [agent] Successfully connected to outputs.file 2023-11-25T16:09:09Z D! [agent] Starting service inputs 2023-11-25T16:09:19Z D! [outputs.file] Wrote batch of 1 metrics in 142.651µs 2023-11-25T16:09:19Z D! [outputs.file] Buffer fullness: 0 / 10000 metrics 2023-11-25T16:09:29Z D! [outputs.file] Wrote batch of 1 metrics in 126.871µs 2023-11-25T16:09:29Z D! [outputs.file] Buffer fullness: 0 / 10000 metrics
Zaujímavejšie však vyzerá súbor /tmp/telegraf.out.
mem,host=linuxos total=8317620224i,inactive=2522996736i,shared=848220160i,write_back=0i,available=3538952192i,huge_pages_free=0i,sreclaimable=1049927680i,swap_total=536866816i,used=3613786112i,commit_limit=4695674880i,high_free=0i,mapped=1177395200i,vmalloc_total=35184372087808i,vmalloc_used=24809472i,buffered=84185088i,slab=1203593216i,swap_cached=87453696i,cached=3088490496i,committed_as=78690824192i,low_total=0i,available_percent=42.547653014843874,dirty=3010560i,high_total=0i,huge_pages_total=0i,vmalloc_chunk=0i,active=2959667200i,huge_page_size=2097152i,low_free=0i,sunreclaim=153665536i,used_percent=43.44735651157328,free=1531158528i,page_tables=32088064i,swap_free=2609152i,write_back_tmp=0i 1700928550000000000 mem,host=linuxos committed_as=78680104960i,huge_pages_total=0i,low_total=0i,vmalloc_total=35184372087808i,available=3531640832i,commit_limit=4695674880i,swap_cached=87453696i,swap_free=2609152i,swap_total=536866816i,vmalloc_used=24866816i,active=2950438912i,free=1522753536i,low_free=0i,vmalloc_chunk=0i,high_free=0i,huge_pages_free=0i,huge_page_size=2097152i,sunreclaim=153661440i,available_percent=42.45975094907146,buffered=84221952i,high_total=0i,shared=848220160i,slab=1203658752i,sreclaimable=1049997312i,write_back=0i,used_percent=43.535209332490915,dirty=4239360i,mapped=1167822848i,total=8317620224i,used=3621093376i,page_tables=30720000i,write_back_tmp=0i,cached=3089551360i,inactive=2523975680i 1700928560000000000 mem,host=linuxos cached=3089911808i,huge_pages_total=0i,mapped=1167765504i,swap_cached=87457792i,buffered=84238336i,commit_limit=4695674880i,high_total=0i,swap_total=536866816i,vmalloc_total=35184372087808i,total=8317620224i,dirty=1708032i,inactive=2524303360i,low_total=0i,free=1534955520i,high_free=0i,huge_pages_free=0i,shared=848220160i,sunreclaim=153698304i,vmalloc_used=24842240i,write_back=0i,available_percent=42.61103114293861,active=2949169152i,committed_as=78673256448i,page_tables=30531584i,sreclaimable=1050013696i,available=3544223744i,used=3608514560i,write_back_tmp=0i,huge_page_size=2097152i,slab=1203712000i,swap_free=2658304i,vmalloc_chunk=0i,used_percent=43.38397838347855,low_free=0i 1700928570000000000
Zo vstupov je povolené len zaznamenávanie obsadenej štatistík operačnej pamäte. Teraz si bližšie rozoberieme jednotlivé polia súboru.
Prvým poľom na každom riadku je vždy názov metriky. V tomto prípade je to mem. Nasleduje zoznam čiarkou oddelených tagov vo forme názov=hodnota. V tomto prípade je názov tagu host a hodnota linuxos. Tagy sú polia, podľa ktorých sú dáta indexované a je možné ich rýchlo prehľadávať. Do tagov by mali byť ukladané len polia, ktoré majú obmedzený počet hodnôt. V riadku ďalej nasleduje zoznam nameraných hodnôt v rovnakej forme, v akej bol zoznam tagov. Posledným poľom je časová pečiatka merania.
Odosielanie dát do InfluxDB
Vo väčšine prípadov budeme chcieť ukladať namerané hodnoty do reálnej databázy. Po pridaní nasledujúcej sekcie sa budú údaje zasielať do InfluxDB:
[[outputs.influxdb_v2]] urls = ["http://127.0.0.1:8086"] organization = "telegraf" bucket = "telegraf" token = "_IQwe0LFcZgILzW-Blre9E9s80FUCo8SgU0lrxAZB-BPFg-HGJvd0zqEMXfL8-YcBR7olvMppvCyQY8_YX6izg=="
URL adresu je potrebné nastaviť podľa hostiteľa a portu, na ktorom beží InfluxDB. Prístupový token je možné získať príkazom influx auth list. Názov organizácie a bucketu musia zodpovedať názvom zvoleným pri inštalácii.
Príprava parsovania logov
Okrem bežných metrík budeme zaznamenávať aj niektoré zaujímavé informácie z logov webového serveru nginx a aplikačného serveru uwsgi. V nasledujúcom výpise je ukážka nginx logu získaného príkazom journalctl -f -o short-iso -u nginx.service:
2023-11-25T17:30:47+0100 linuxos nginx[3852772]: linuxos linuxos_sk: GET 302 0.003(ms) 486(B) upstream[response=0.003(ms) ttfb=0.003(ms)] x.x.x.181 /currency/set/?currency=EUR Mozilla/5.0 2023-11-25T17:30:47+0100 linuxos nginx[3852774]: linuxos linuxos_sk: POST 200 0.028(ms) 867(B) upstream[response=0.027(ms) ttfb=0.027(ms)] x.x.x.54 /accounts/signup/ Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:109.0) Gecko/20100101 Firefox/119.0
Do pozornosti dávam názov webu linuxos_sk, ktorý sa nedal zapísať s bodkou. Našťastie je možné problém veľmi jednoducho napraviť pomocou nástroja awk. Výsledný skript /etc/telegraf/scripts/read_nginx_log.sh bude vyzerať nasledovne:
#!/bin/bash /usr/bin/journalctl -f -o short-iso -u nginx.service|awk '\ {\ gsub(/_/, ".", $5);\ print\ }'
Podobným spôsobom bude implementovaný skript pre čítanie uwsgi logov. Konfigurácia bude o niečo zložitejšia, keďže tu sa spracúva dĺžka behu skriptu. Z rýchlych dotazov sa odstráni URL adresa a otagujú sa značkou fast. Pomalé sa zase otagujú značkou slow a URL adresa zostane. Takto vyzerá skript /etc/telegraf/scripts/read_uwsgi_log.sh:
#!/bin/bash
/usr/bin/journalctl -f -o short-iso -u emperor.uwsgi.service | awk '\
{\
time = substr($6, 1, length($6)-2);\
speed = "slow";\
if (time+0 < 1000) {\
$8 = "∅";\
speed = "fast"\
}\
print $1, $2, $3, $4, $5, $6, $7, speed, $8\
}'
Výsledný log vyzerá približne takto:
2023-11-25T17:45:42+0100 linuxos linuxos.sk[288892]: GET 200 112ms 103501b fast ∅ 2023-11-25T17:45:43+0100 linuxos linuxos.sk[288892]: GET 200 148ms 108156b fast ∅ 2023-11-25T17:45:44+0100 linuxos linuxos.sk[288892]: GET 200 93ms 102613b fast ∅
Kompletná konfigurácia
V tejto časti si prejdeme plne funkčný konfiguračný súbor pre telegraf. Finálny /etc/telegraf/telegraf.conf vyzerá takto:
# Ukladanie do InfluxDB [[outputs.influxdb_v2]] urls = ["http://127.0.0.1:8086"] organization = "telegraf" bucket = "telegraf" token = "_IQwe0LFcZgILzW-Blre9E9s80FUCo8SgU0lrxAZB-BPFg-HGJvd0zqEMXfL8-YcBR7olvMppvCyQY8_YX6izg==" # Aktivita CPU [[inputs.cpu]] percpu = true totalcpu = true collect_cpu_time = false report_active = false # Zaplnenie disku [[inputs.disk]] ignore_fs = ["tmpfs", "devtmpfs", "devfs", "iso9660", "overlay", "aufs", "squashfs"] # Monitorovanie RAM [[inputs.mem]] # Monitorovanie siete [[inputs.net]] interfaces = ["eth0"] # Monitorovanie procesov (+ pridanie tagov socket podľa používateľa) [[inputs.procstat]] user = "linuxos.sk" [inputs.procstat.tags] socket = "linuxos.sk" [[inputs.procstat]] user = "mirec" [inputs.procstat.tags] socket = "mirec.sk" # Monitorovanie uWSGI procesov [[inputs.uwsgi]] servers = ["unix:///run/uwsgi/stats/linuxos.sk.sock"] [inputs.uwsgi.tags] socket = "linuxos.sk" [[inputs.uwsgi]] servers = ["unix:///run/uwsgi/stats/mirec.sk.sock"] [inputs.uwsgi.tags] socket = "mirec.sk" # Ukladanie uWSGI logov (kvôli záznamu najpomalších URL) [[inputs.execd]] command = ["/etc/telegraf/scripts/read_uwsgi_log.sh"] grok_patterns = ['%{TIMESTAMP_ISO8601:timestamp} %{DATA:username} uwsgi-%{DATA:socket:tag}\[%{NUMBER:pid:int}\]: %{DATA:method:tag} %{NUMBER:response_code:tag} %{NUMBER:uwsgi_request_time:float}ms %{NUMBER:bytes:int}b %{WORD:speed:tag} %{GREEDYDATA:url}'] data_format = "grok" name_override = "uwsgi_requests" fielddrop = ["username", "pid"] # Rovnaké spracovanie uWSGI logov, tentoraz za účelom výpočtu histogramu [[inputs.execd]] command = ["/etc/telegraf/scripts/read_uwsgi_log.sh"] grok_patterns = ['%{TIMESTAMP_ISO8601:timestamp} %{DATA:username} uwsgi-%{DATA:socket:tag}\[%{NUMBER:pid:int}\]: %{DATA:method} %{NUMBER:response_code} %{NUMBER:uwsgi_request_time:float}ms %{NUMBER:bytes:int}b %{WORD:speed} %{GREEDYDATA:url}'] data_format = "grok" name_override = "uwsgi_requests_histogram" fielddrop = ["timestamp", "username", "pid", "method", "response_code", "bytes", "speed", "url"] # Rozdelenie počtu requestov do bucketov podľa trvanie requestu po 20ms [[aggregators.histogram]] period = "120s" drop_original = true reset = true cumulative = false namepass = ["uwsgi_requests_histogram"] [[aggregators.histogram.config]] measurement_name = "uwsgi_requests_histogram" fields = ["uwsgi_request_time"] buckets = [20.0, 40.0, 60.0, 80.0, 100.0, 120.0, 140.0, 160.0, 180.0, 200.0, 220.0, 240.0, 260.0, 280.0, 300.0, 320.0, 340.0, 360.0, 380.0, 400.0, 420.0, 440.0, 460.0, 480.0, 500.0, 520.0, 540.0, 560.0, 580.0, 600.0, 620.0, 640.0, 660.0, 680.0, 700.0, 720.0, 740.0, 760.0, 780.0, 800.0, 820.0, 840.0, 860.0, 880.0, 900.0, 920.0, 940.0, 960.0, 980.0, 1000.0, 60000.0] # Spracovanie logov nginx [[inputs.execd]] command = ["/etc/telegraf/scripts/read_nginx_log.sh"] data_format = "grok" grok_patterns = ["%{TIMESTAMP_ISO8601:timestamp} %{WORD:server} nginx\\[%{NUMBER:nginx_pid}\\]: %{DATA:server_name} %{DATA:socket:tag}: %{WORD:http_method:tag} %{NUMBER:http_status:tag} %{NUMBER:request_time:float}\\(ms\\) %{NUMBER:bytes_sent:int}\\(B\\) upstream\\[response=%{NUMBER:upstream_response_time:float}\\(ms\\) ttfb=%{NUMBER:upstream_ttfb:float}\\(ms\\)\\] %{IP:client_ip} %{DATA:request_path} %{GREEDYDATA:user_agent}"] fielddrop = ["server", "nginx_pid", "server_name", "client_ip", "request_path", "user_agent", "bytes_sent", "upstream_response_time", "ttfb"] name_override = "nginx_access"
Vstup inputs.cpu slúži na monitorovanie stavu CPU. V čase písania článku tento modul exportuje tag cpu s číslom jadra (cpux alebo cpu-total) a polia:
- time_user
- time_system
- time_idle
- time_nice
- time_iowait
- time_irq
- time_softirq
- time_steal
- time_guest
- time_guest_nice
- usage_user (%)
- usage_system (%)
- usage_idle (%)
- usage_nice (%)
- usage_iowait (%)
- usage_irq (%)
- usage_softirq (%)
- usage_steal (%)
- usage_guest (%)
- usage_guest_nice (%)
Ďalší vstup inputs.disk slúži na zaznamenávanie zaplnenia disku. Dostupné tagy sú:
- fstype (typ FS)
- device (názov zariadenia)
- path (cesta k bodu pripojenia)
- mode (rw / ro podľa toho, či je pripojený na zápis/čítanie)
- label (devicemapper štítok)
Z polí máme k dispozícii:
- free (byty)
- total (byty)
- used (byty)
- used_percent (%)
- inodes_free (počet súborov)
- inodes_total (počet súborov)
- inodes_used (počet súborov)
- inodes_used_percent (%)
Ďalšie 2 sekcie slúžia na konfiguráciu zaznamenávania stavu RAM a sieťovej karty eth0.
Zaujímavejšou sekciou je inputs.procstat, ktorá slúži na zaznamenávanie štatistík o procesoch. Nakonfigurovaných je niekoľko vstupov, pričom vstupy sú filtrované podľa používateľa. Každý vstup má nakonfigurovanú značku socket, aby bolo možné dáta zoskupiť podľa konkrétneho webu.
Konfiguráciu štatistík v nastavení uWSGI sme samozrejme nerobili len tak prenič-zanič. Nástroj telegraf vstavanú podporu pre čítanie štatistík uWSGI pomocou sekcie inputs.uwsgi. Podobne, ako pri inputs.procstat je aj tu nakonfigurované značkovanie webu do tagu socket.
Skutočná zábava sa začína až teraz pri vstupoch, ktoré obsahujú grok_patterns. Teda začala by … nebyť ChatGPT 4. Ja som nepoznal formát grok_paterns, dokonca som ani nepoznal spôsob, ako nakonfigurovať telegraf tak, aby čítal log. Napísal som však požiadavku pre ChatGPT4, aby mi napísal konfiguráciu telegrafu pre čítanie logu, pridal som jeden riadok z logu ako ukážku a on na mňa vyhodil:
[[inputs.execd]] command = ["/etc/telegraf/scripts/read_uwsgi_log.sh"] grok_patterns = ['%{TIMESTAMP_ISO8601:timestamp} %{DATA:username} uwsgi-%{DATA:socket:tag}\[%{NUMBER:pid:int}\]: %{DATA:method:tag} %{NUMBER:response_code:tag} %{NUMBER:uwsgi_request_time:float}ms %{NUMBER:bytes:int}b %{WORD:speed:tag} %{GREEDYDATA:url}'] data_format = "grok" name_override = "uwsgi_requests" fielddrop = ["username", "pid"]
Vážne, neviem ako sa to konfiguruje a nebyť ChatGPT by som sa trápil veľmi dlho. Výsledkom je pekne štruktúrovaný výstup, ktorý je správne otagovaný a odosielaný do InfluxDB.
Druhý prakticky identický vstup inputs.execd slúži ako vstup pre výpočet histogramu. Agregačná funkcia aggregators.histogram automaticky sčítava výskyty záznamu podľa ich hodnoty a tagov do jednotlivých bucketov. To je aj dôvod, prečo druhý vstup neobsahuje napríklad tag speed.
Nakoniec tu máme spracovanie logu webového servera. Rovnako ako v prípade uWSGI som požiadal ChatGPT o napísanie konfigurácie. Zase bez problémov a bez našepkávania rozpoznal polia v logu a všetko viac-menej správne priradil s použitím minimálneho kontextu. Konečne mám kolegu, ktorému môžem nakladať špinavú prác!
Grafana
Pre inštaláciu je podľa dokumentácie potrebné vykonať niekoľko príkazov:
apt-get install -y apt-transport-https software-properties-common wget mkdir -p /etc/apt/keyrings/ wget -q -O - https://apt.grafana.com/gpg.key | gpg --dearmor | tee /etc/apt/keyrings/grafana.gpg > /dev/null echo "deb [signed-by=/etc/apt/keyrings/grafana.gpg] https://apt.grafana.com stable main" | tee -a /etc/apt/sources.list.d/grafana.list echo "deb [signed-by=/etc/apt/keyrings/grafana.gpg] https://apt.grafana.com beta main" | tee -a /etc/apt/sources.list.d/grafana.list apt-get update apt-get install grafana
Následne sa grafana naštartuje príkazom systemctl start grafana-server. Teraz stačí povoliť pripojenie na port 3000 (napríklad ufw allow 3000) a po načítaní adresy http://adresa-servera:3000/ v prehliadači by sa malo zobraziť prihlasovacie okno.
Úvodné prihlasovacie meno a heslo je admin / admin.
Ďalej je potrebné nastaviť zdroj dát. Ten sa nastavuje cez Menu / Connections a z dostupných spojení vyberieme InfluxDB. Dôležité je vybrať jazyk Flux. Následne je potrebné nastaviť minimálne URL adresu a prihlasovacie údaje tak, ako boli nastavené v konfigurácii telegrafu.
Následne sa môžeme začať hrať s dátami kliknutím na Explore data.
CPU
Na rozdiel do zdrojov Prometheus, alebo InfluxDB s jazykom InfluxQL nie je pre jazyk Flux dostupný grafický editor. Všetky dotazy preto musia byť písané ručne pomocou textového editoru.
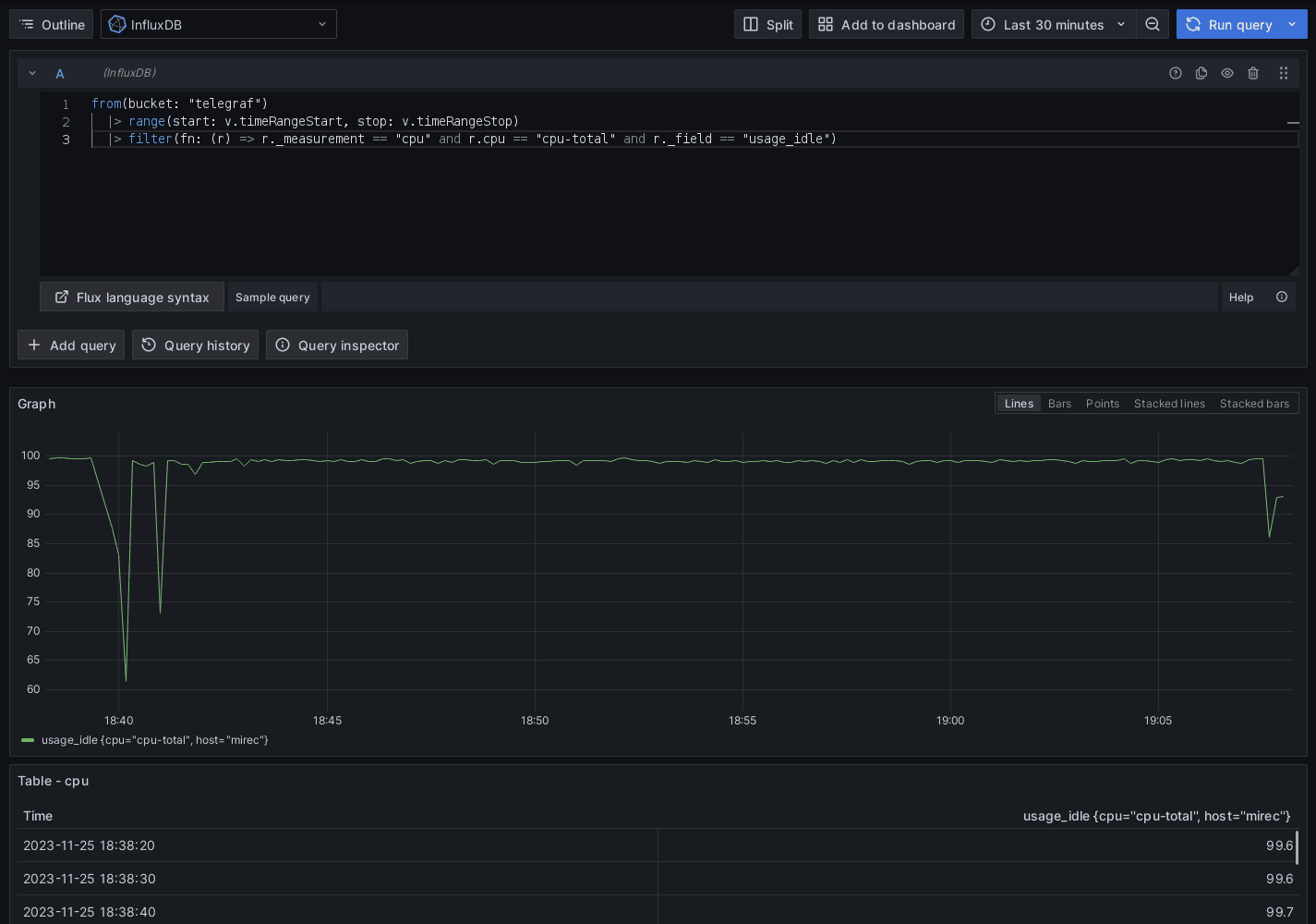
Graf CPU bol vykreslený nasledujúcim dotazom:
from(bucket: "telegraf")
|> range(start: v.timeRangeStart, stop: v.timeRangeStop)
|> filter(fn: (r) =>
r._measurement == "cpu" and
r.cpu == "cpu-total" and
r._field == "usage_idle"
)
Príkaz from vyberá bucket, z ktorého bud čítané dáta. Nasleduje obmedzenie časového rozsahu pomocou vstavanej premennej v. Túto premennú nastavuje automaticky grafana podľa rozsahu, ktorý sa nastavuje v hornej časti rozhrania grafany. Ďalej nasleduje konkrétny výber dát. Tu zdôrazňujem, že každé pole v dátach je reprezentované ako samostatný riadok. Riadky majú priradené tagy ako r.tag. Riadky obsahujú aj implicitné premenné začínajúce sa na znak _. Sú to napríklad:
- _measurement
- Názov metriky
- _field
- Názov poľa
- _value
- Hodnota poľa
- _time
- Časová pečiatka
V štatistikách CPU nie je k dispozícii celkové zaťaženie, ale máme tu k dispozícii pole usage_idle. Ak by sme chceli zobraziť celkové zaťaženie, stačí nám odčítať dobu nečinnosti od 100%. Na konci dotazu stačí jednoducho pridať funkciu map, ktorá aplikuje funkciu na každý bod:
from(bucket: "telegraf")
|> range(start: v.timeRangeStart, stop: v.timeRangeStop)
|> filter(fn: (r) =>
r._measurement == "cpu" and
r.cpu == "cpu-total" and
r._field == "usage_idle"
)
|> map(fn: (r) => ({ r with _value: 100.0 - r._value }))
Tento dotaz je vysoko neoptimálny, pretože vyberá všetky dátové body bez ohľadu na to, či je zobrazený graf široký, alebo úzky. Grafana má automatickú premennú v.windowPeriod, ktorá určuje, aký časový úsek zaberá približne pixel v zobrazenom grafe. Pri zobrazení záťaže CPU je ideálne rozdeliť dáta na časové okná a v každom časovom okne vypočítať priemernú hodnotu. Presne na toto slúži funkcia aggregateWindow:
from(bucket: "telegraf")
|> range(start: v.timeRangeStart, stop: v.timeRangeStop)
|> filter(fn: (r) =>
r._measurement == "cpu" and
r.cpu == "cpu-total" and
r._field == "usage_idle"
)
|> map(fn: (r) => ({ r with _value: 100.0 - r._value }))
|> aggregateWindow(every: v.windowPeriod, fn: mean)
Momentálne prijímame síce dáta len z jediného serveru, ale v reálnom nasadení môžeme mať serverov výrazne viacej. Preto je vhodné nastaviť zoskupenie dát podľa hostiteľa, vďaka čomu budú v grafe jednotlivé servery zobrazené samostatnou krivkou. Zoskupenie sa nastavuje volaním funkcie group pred agregačnou funkciou.
from(bucket: "telegraf")
|> range(start: v.timeRangeStart, stop: v.timeRangeStop)
|> filter(fn: (r) =>
r._measurement == "cpu" and
r.cpu == "cpu-total" and
r._field == "usage_idle"
)
|> map(fn: (r) => ({ r with _value: 100.0 - r._value }))
|> group(columns: ["host"])
|> aggregateWindow(every: v.windowPeriod, fn: mean)
Nový dashboard sa dá vytvoriť kliknutím na tlačidlo Add to dashboard.
Nasleduje malá ukážka nastavení grafu CPU:
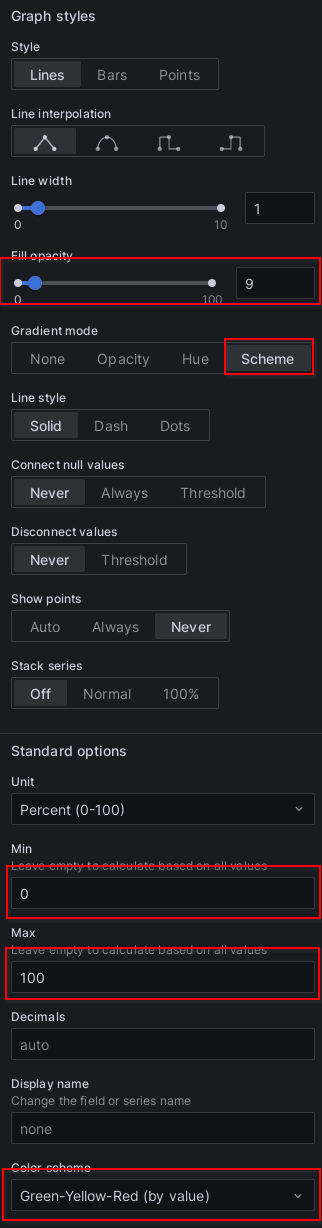
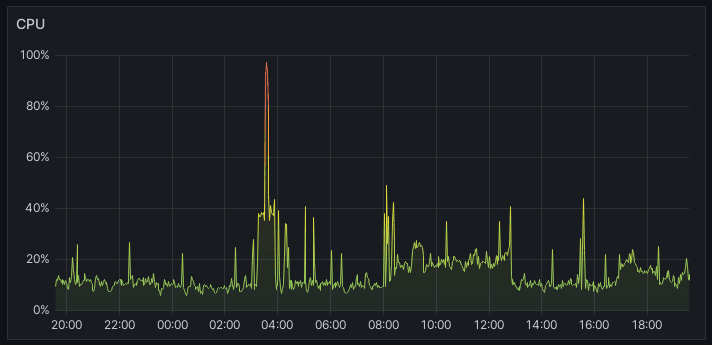
Výsledný graf môže vyzerať celkom elegantne:
Disk
Aktuálne zaplnenie disku sda sa dá zistiť nasledujúcim dotazom:
from(bucket: "telegraf")
|> range(start: v.timeRangeStart, stop: v.timeRangeStop)
|> filter(fn: (r) =>
r._measurement == "disk" and
r.device == "sda" and
r._field == "used_percent"
)
|> group(columns: ["host"])
|> last()
Funkcia last znamená, že z dát chceme vybrať len poslednú hodnotu. Typ grafu je v tomto prípade Gauge. Po nastavení príslušných limitov a farbičiek je na svete pekný ukazovateľ zaplnenia disku. Rovnakým spôsobom je možné vytvoriť aj časové priebehy, akurát sa namiesto last použije aggregateWindow.
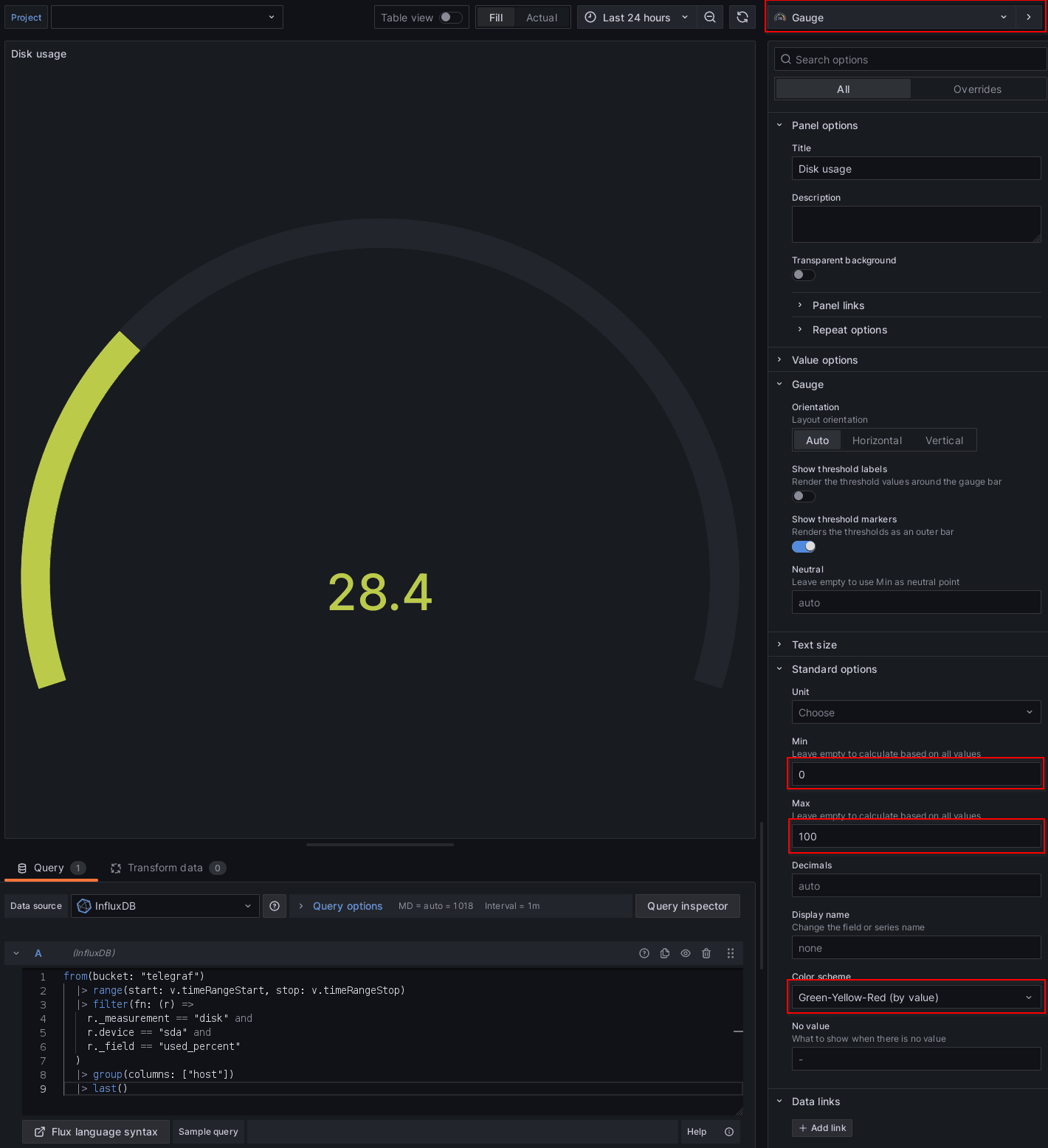
Sieťová aktivita
Pri monitorovaní sieťovej aktivity zvyčajne požadujeme zobrazenie prenosovej rýchlosti. Medzi dátami, ktoré sprístupňuje telegraf však nie je prenosová rýchlosť, ale iba celkové množstvo prenesených dát jedným či druhým smerom. Preto budeme musieť v tomto prípade využiť nové príkazy pivot a derivative.
Kompletný dotaz pre získanie sieťovej aktivity vyzerá tato:
from(bucket: "telegraf")
|> range(start: v.timeRangeStart, stop: v.timeRangeStop)
|> filter(fn: (r) =>
r._measurement == "net" and
(r._field == "bytes_recv" or r._field == "bytes_sent")
)
|> pivot(rowKey:["_time"], columnKey: ["_field"], valueColumn: "_value")
|> map(fn: (r) => ({ _value: r.bytes_recv + r.bytes_sent, _time: r._time, host: r.host }))
|> group(columns: ["host"])
|> aggregateWindow(every: v.windowPeriod, fn: max)
|> derivative(unit: 1s, nonNegative: true)
Dotazy v databáze InfluxDB umožňujú získať len jedinú hodnotu parametra, ktorá bude uložená vo vstavanej premennej r._value. Je síce možné vybrať všetky hodnoty, ktoré majú v poli r._field názov bytes_recv alebo bytes_sent, ale v takom prípade by sa pracovalo ako so samostatnými riadkami v tabuľke.
Pre spojenie niekoľkých hodnôt do jediného záznamu slúži funkcia pivot, ktorá podľa kľúča rowKey a vybraných parametrov, napríklad _field pozbiera hodnoty z valueColumn a umiestní ich do záznamu. Výsledkom je v tomto prípade záznam, ktorému pribudli stĺpce bytes_recv a bytes_recv.
Funkciou map sa následne hodnoty sčítajú a uložia do vstavanej premennej _value. Po zoskupení podľa hostiteľa a agregácii v časových oknách dostaneme hodnotu maxima prenesených dát na zariadení. To by však vykreslilo len stúpajúcu krivku. My však chceme vykresliť prenosovú rýchlosť, teda zmenu prenesených dát v čase. Práve na to slúži funkcia derivative.
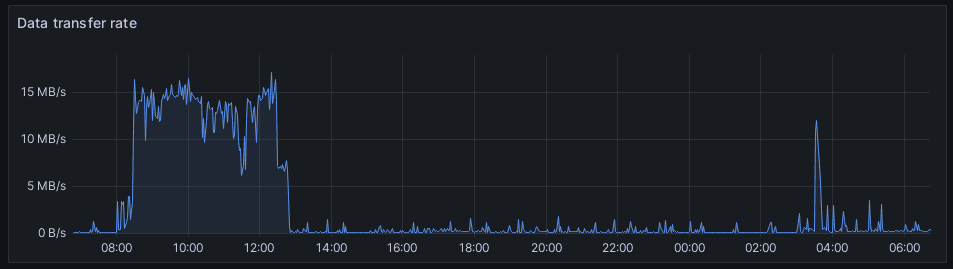
Záťaž CPU podľa webu
Pri tomto dotaze síce nie sú použité žiadne nové príkazy, ale napriek tomu si zaslúži pozornosť vďaka spôsobu postupného použitia agregačných funkcií. Celý dotaz vyzerá nasledovne:
from(bucket: "telegraf")
|> range(start: v.timeRangeStart, stop: v.timeRangeStop)
|> filter(fn: (r) =>
r._measurement == "procstat" and
(r._field == "cpu_usage" or r._field == "pid")
)
|> pivot(rowKey:["_time"], columnKey: ["_field"], valueColumn: "_value")
|> map(fn: (r) => ({ _time: r._time, _value: r.cpu_usage, pid: r.pid, socket: r.socket }))
|> window(every: v.windowPeriod)
|> group(columns: ["_start", "pid", "socket"])
|> mean()
|> group(columns: ["_start", "socket"])
|> sum()
|> group(columns: ["_time", "socket"])
Pri výbere dát nás budú zaujímať hodnoty cpu_usage a pid. Keďže sú to 2 hodnoty, je potrebné znovu dáta z viacerých riadkov usporiadať do stĺpcov funkciou pivot. Dáta sú následne usporiadané do nového záznamu funkciou map a rozdelené na časové úseky funkciou window.
Nasleduje zvláštna séria agregačných funkcií. V prvom rade sa pre každý úsek vypočíta priemerná hodnota záťaže CPU každého procesu. Následne sa vypočíta súčet (sum) záťaže CPU jednotlivých procesov patriacich webu (socket). Výsledok je nakoniec preskupený tak, aby sa dal vykresliť v grafe. Tentoraz som pre vizualizáciu vybral typ grafu Heatmap s farebnou škálou Turbo.
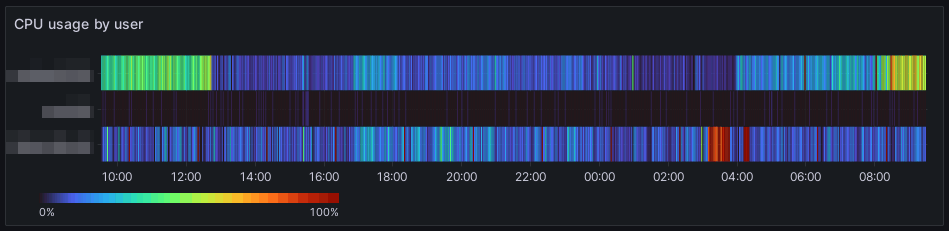
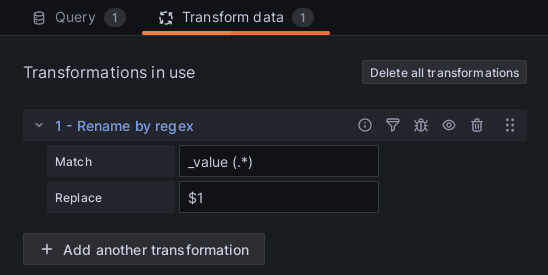
Grafana v aktuálnej verzii zobrazuje názvy nameraných hodnôt ako _value názov webu. Odstránenie prebytočného _value je možné vykonať na karte transformácií.
Zaujímavejšia by bola štatistika priemerného využitia CPU podľa webu za určité obdobie. V tomto prípade bude stratégia výpočtu na jednej strane trochu jednoduchšia, ale na druhej strane spôsob zápisu tak jednoduchý nebude. Princípom bude sčítanie všetkých hodnôt cpu_usage zoskupených podľa webu (socket) a následne ich vydelenie počtom časových okamihov, v ktorých bolo vykonané meranie. Nasledujúci dotaz vyzerá pomerne zložito, ale v skutočnosti sa skladá z 2 jednoduchých častí.
countTimestamps = from(bucket: "telegraf")
|> range(start: -24h)
|> filter(fn: (r) => r._measurement == "procstat" and r._field == "cpu_usage")
|> keep(columns: ["_time", "_measurement"])
|> distinct(column: "_time")
|> map(fn: (r) => ({ r with _value: 1 }))
|> count(column: "_value")
|> findColumn(fn: (key) => true, column: "_value")
from(bucket: "telegraf")
|> range(start: -24h)
|> filter(fn: (r) => r._measurement == "procstat" and r._field == "cpu_usage")
|> window(every: 24h)
|> group(columns: ["socket"])
|> sum()
|> map(fn: (r) => ({ r with _value: r._value / float(v: countTimestamps[0]) }))
|> group()
Prvá časť zistí počet časových okamihov a uloží ich do jednoprvkového poľa countTimestamps. Prvou novou funkciou v tejto časti je keep, ktorá ponechá len vybrané stĺpce. Mimochodom opakom funkcie keep je funkcia drop, ktorá naopak vybrané stĺpce zahodí.
Funkcia distinct ponechá unikátne hodnoty vybraného stĺpca. Následne sa hodnoty funkciou modifikujú na formát {_value: 1, _time: čas}. Dôvodom tejto divnej transformácie je, že nasledujúca agregačná funkcia count sa nedá použiť na výsledok distinct.
Nasleduje už len extrakcia hodnoty z prúdu dát. Funkcia findColumn nájde v prúde všetky riadky zodpovedajúce predikátu v fn a extrahuje z nich hodnotu column do poľa. V tomto prípade chceme extrahovať hodnotu _value. Výsledkom je teda jednoprvkové pole keďže na vstupe bol len jeden riadok.
Druhou časťou je klasický súčet zoskupený podľa webu, ktorého hodnota je vydelená počtom časových okamihov vo vzorke dát.
Výsledkom pri použití Bar gauge je elegantný stĺpcový graf.

Aby boli dáta pekne zoradené od najviac vyťaženého webu, po najmenej vyťažený, je možné na konci pridať volanie funkcie |> sort(columns: ["_value"], desc: true), alebo jednoducho transformovať údaje v grafane vstavanou transformačnou funkciou Sort by.
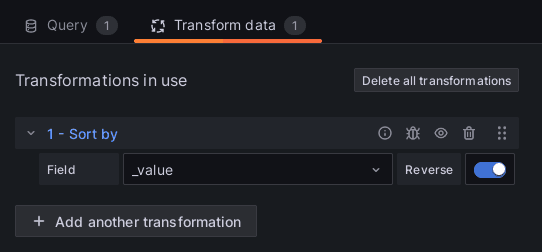
Počet dotazov na uWSGI
Nasledujúci graf bude zobrazovať priemerný počet požiadaviek za 5 minút. Dáta budú získavané z metriky uwsgi_apps, ktorú poskytuje inputs.uwsgi. Špecialitou v tomto prípade bude, že okno bude síce variabilné, ale minimálna dĺžka okna bude 300s. Zároveň ak bude perióda dlhšia, bude nutné súčet vydeliť príslušným koeficientom, aby bol stále zobrazený počet dotazov za obdobie 5 minút. Výsledný dotaz vyzerá takto:
minPeriod = 300s
windowPeriod = if int(v: v.windowPeriod) > int(v: minPeriod) then v.windowPeriod else minPeriod
periodValueAdjustment = float(v: int(v: minPeriod)) / float(v: int(v: windowPeriod))
from(bucket: "telegraf")
|> range(start: v.timeRangeStart, stop: v.timeRangeStop)
|> filter(fn: (r) => r._measurement == "uwsgi_apps" and r._field == "requests")
|> difference(nonNegative: true)
|> group(columns: ["socket"])
|> aggregateWindow(every: duration(v: windowPeriod), fn: sum)
|> map(fn: (r) => ({ r with _value: float(v: r._value) * periodValueAdjustment }))
Na začiatku je definovaná minimálna perióda. Následne sa do windowPeriod uloží používateľom nastavená hodnota, alebo minimálna. Ak sa pýtate, prečo sa perióda stále pretypuje volaním int na celé číslo, je to preto, lebo operácie porovnania nie sú pre typ duration definované. Poslednou z premenných je koeficient, ktorým sa musí násobiť súčet dotazov v prípade, že požadovaná perióda je dlhšia než 300s.
Nasleduje už klasický výber a transformácia dát zoskupených podľa webu. Výsledok je vhodné zobraziť napríklad v čiarovom grafe s nastavením Stack series na Normal.
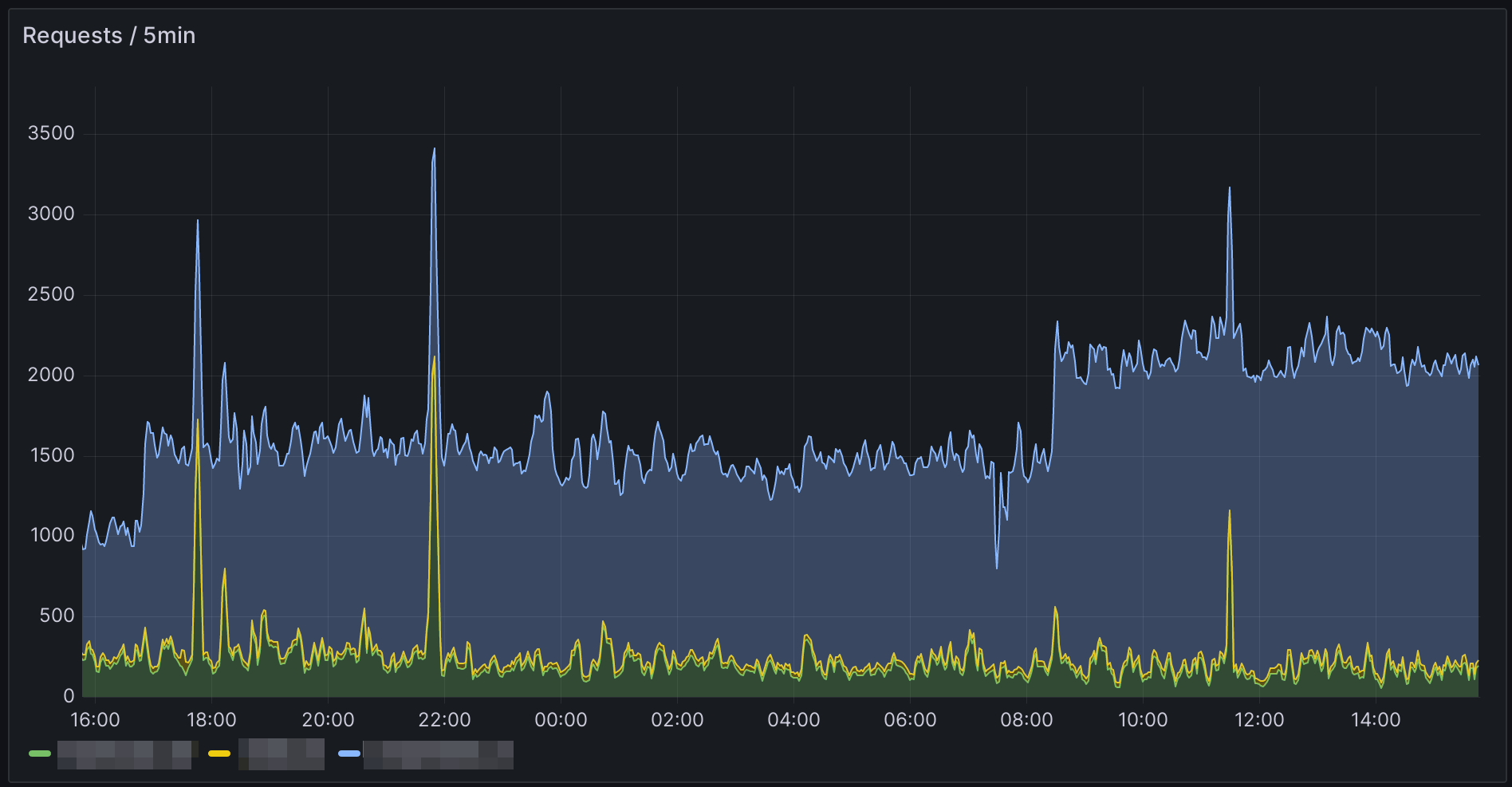
Podobným spôsobom je možné získať aj celkový počet dotazov za určité obdobie. Výsledok sa dá opäť zobraziť napríklad cez Bar gauge.
from(bucket: "telegraf") |> range(start: -24h) |> filter(fn: (r) => r._measurement == "uwsgi_apps" and r._field == "requests") |> difference(nonNegative: true) |> group(columns: ["socket"]) |> sum() |> group() |> sort(columns: ["_value"], desc: true)

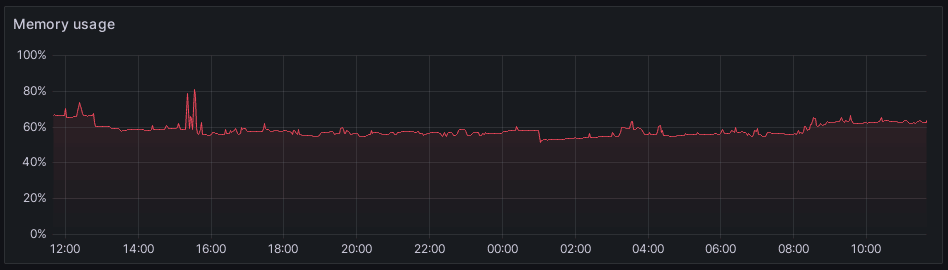
Monitoring RAM
Pri zobrazení obsadenej pamäte postačia už nadobudnuté vedomosti. Aby bola výsledkom percentuálna hodnota, stačí vydeliť obsadenú pamäť celkovou dostupnou pamäťou, čo sa deje vo volaní funkcie map:
from(bucket: "telegraf")
|> range(start: v.timeRangeStart, stop: v.timeRangeStop)
|> filter(fn: (r) => r._measurement == "mem" and (r._field == "total" or r._field == "available"))
|> pivot(rowKey:["_time"], columnKey: ["_field"], valueColumn: "_value")
|> map(fn: (r) => ({ _value: float(v: r.total - r.available) / float(v: r.total), _time: r._time }))
|> group(columns: ["host"])
|> aggregateWindow(every: v.windowPeriod, fn: mean)
Výsledok sa dá vykresliť napríklad v jednoduchom čiarovom grafe:
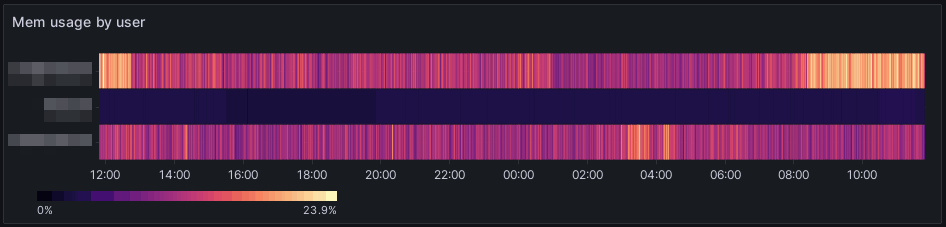
Rovnakou technikou, ako pri CPU je možné rozdeliť spotrebovanú pamäť medzi jednotlivé weby:
from(bucket: "telegraf")
|> range(start: v.timeRangeStart, stop: v.timeRangeStop)
|> filter(fn: (r) =>
r._measurement == "procstat" and
(r._field == "memory_usage" or r._field == "pid")
)
|> pivot(rowKey:["_time"], columnKey: ["_field"], valueColumn: "_value")
|> map(fn: (r) => ({ r with _value: r.memory_usage }))
|> window(every: v.windowPeriod)
|> group(columns: ["_start", "pid", "socket"])
|> max()
|> group(columns: ["_start", "socket"])
|> sum()
|> group(columns: ["_time", "socket"])
Pri vykreslení je zase použitý Heatmap s farebnou schémou Magma.
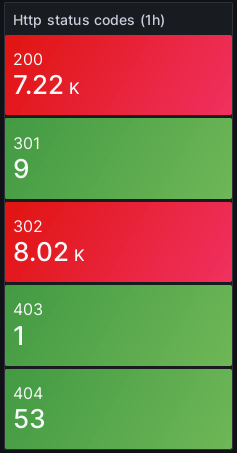
Štatistiky HTTP stavov
Niekedy môže chybné fungovanie webového serveru prezradiť aj pomer HTTP stavových kódov. Napríklad zvýšený počet stavu 503 môže znamenať preťažený server. Počet požiadaviek podľa stavu sa dá získať jednoduchým dotazom metriky nginx_access.
from(bucket: "telegraf") |> range(start: -1h) |> filter(fn: (r) => r._measurement == "nginx_access" and r._field == "request_time") |> group(columns: ["http_status"]) |> count() |> group()
Vhodnou vizualizáciou pre tento typ dát je napríklad Stat.
Najpomalšie URL adresy
Veľmi užitočnou pomôckou pri diagnostike a optimalizácii je zoznam najpomalších URL adries. Nasledujúci dotaz využíva polia uwsgi_request_time a url z metriky uwsgi_requests, pričom sa využívajú len URL adresy označené tagom slow.
from(bucket: "telegraf")
|> range(start: -1h)
|> filter(fn: (r) =>
r._measurement == "uwsgi_requests" and
r.speed == "slow" and
(r._field == "uwsgi_request_time" or r._field == "url")
)
|> pivot(rowKey:["_time"], columnKey: ["_field"], valueColumn: "_value")
|> map(fn: (r) => ({ r with _value: r.uwsgi_request_time }))
|> group(columns: ["socket", "url"])
|> mean()
|> group()
|> top(n: 100, columns: ["_value"])
Pre každú URL adresu sa najskôr vypočíta priemerný čas odpovede. Nakoniec sa vyberie 100 záznamov s najvyššou hodnotou stĺpca _value. Vhodnou vizualizáciou pre tento typ dát je Table.
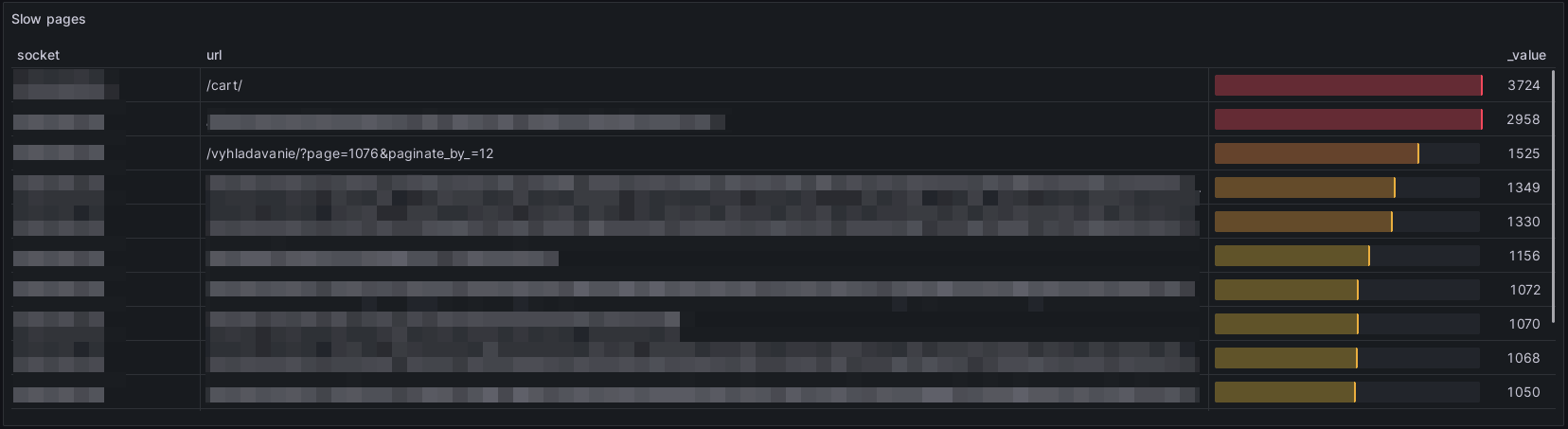
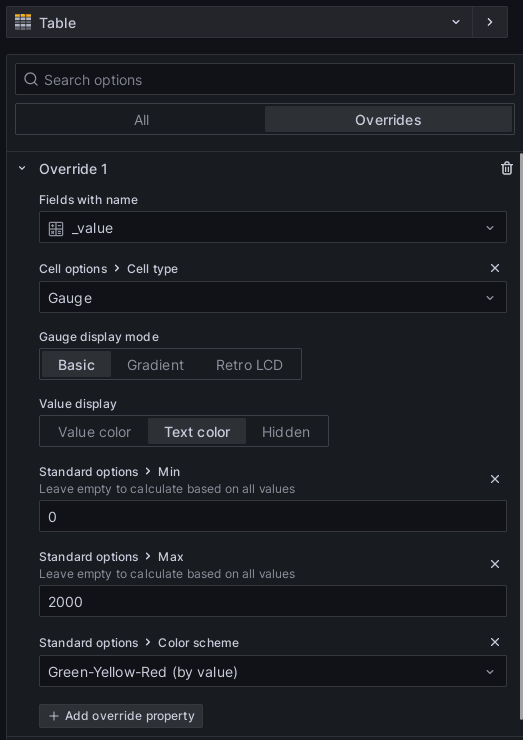
Stĺpce tabuľky štandardne zobrazujú textovú hodnotu. V prípade, že chceme zmeniť spôsob zobrazenia stĺpcov napríklad na stĺpcový graf, dá sa to cez nastavenia tabuľky na karte overrides. Na nasledujúcom obrázku je nastavenie pre pole s názvom _value.
Šablóny
Často je prehľadnejšie zobrazenie samostatnej sady grafov pre každý web. Opakovaná konfigurácia presne tých istých dotazov a grafov, akurát s jediným rozdielnym filtrom socket = "projekt" by bola pekná nuda. Našťastie je tu možnosť generovať sadu grafov pomocou šablón.
Konfiguráciu začneme pridaním premennej so zoznamom webov. Premenné sa editujú cez tlačidlo nastavenia dashboardu (ozubené koliesko v hornej časti) a sekciu Variables.
Naša premenná bude typu Custom, bude sa volať Project a bude mať viac hodnôt (Multi-value). Hodnoty sa vkladajú ako text oddelený čiarkami.
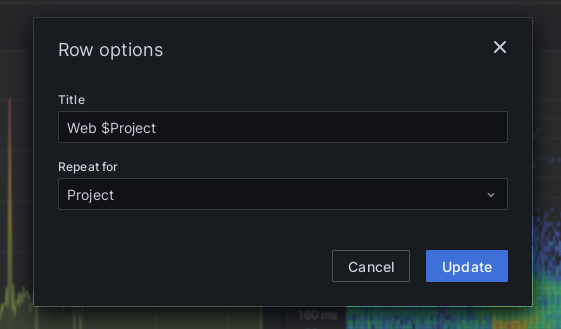
V zobrazení dashboardu na vrchnej časti pribudlo pole výberu projektu. Aby boli zobrazené grafy pre konkrétne projekty, je potrebné vytvoriť nové elementy, ktoré majú povolené opakovanie. Osobne odporúčam najskôr vytvoriť Row a cez tlačidlo ozubeného kolesa mu nastaviť šablónu titulku a opakovanie podľa projektu.
Akékoľvek ďalšie zobrazenia pridané do elementu Row budú automaticky opakované pre projekt.
S podobným dotazom, ktorý zobrazuje CPU záťaž webu sme sa už stretli. Tu však ubudlo zoskupenie podľa webu a naopak pribudol konkrétny web do volania funkcie filter. Namiesto názvu projektu sa používa zástupný symbol ${Project:raw}.
from(bucket: "telegraf")
|> range(start: v.timeRangeStart, stop: v.timeRangeStop)
|> filter(fn: (r) =>
r._measurement == "procstat" and
r.socket == "${Project:raw}" and
(r._field == "cpu_usage" or r._field == "pid")
)
|> pivot(rowKey:["_time"], columnKey: ["_field"], valueColumn: "_value")
|> map(fn: (r) => ({ _time: r._time, _value: r.cpu_usage, pid: r.pid, socket: if exists r.socket then r.socket else "" }))
|> window(every: v.windowPeriod)
|> group(columns: ["_start", "pid"])
|> mean()
|> group(columns: ["_start"])
|> sum()
|> group(columns: ["_time"])
Histogram s časom odpovede
Našu úmornú a strastiplnú cestu zakončím svätým grálom vizualizácií. Samotný dotaz patrí skôr k tým jednoduchším, aj keď má svoje špecifiká:
import "math"
windowPeriodBase = int(v: 120s)
windowPeriodCount = int(v: math.ceil(x: float(v: int(v: v.windowPeriod)) / float(v: windowPeriodBase)))
windowPeriod = duration(v: windowPeriodBase * windowPeriodCount)
from(bucket: "telegraf")
|> range(start: v.timeRangeStart, stop: v.timeRangeStop)
|> filter(fn: (r) =>
r._measurement == "uwsgi_requests_histogram" and
r.socket == "${Project:raw}" and
r._field == "uwsgi_request_time_bucket"
)
|> group(columns: ["le"])
|> aggregateWindow(every: windowPeriod, fn: sum)
|> map(fn: (r) => ({
r with _value:
if exists(r._value) then
math.log2(x: float(v: r._value) + 1.0)
else
0.0
})
)
Na začiatku súboru je výpočet periódy podľa hodnoty, ktorú nastavil používateľ. Keďže dáta histogramu sa ukladajú každých 120s, minimálna hodnota je 120s. Aby sa dáta zobrazovali bez anomálií keďže sa zobrazuje súčet v okne, je nutné používať celé násobky hodnoty 120. Práve preto sa počet periód zaokrúhľuje na celé čísla smerom nahor volaním math.ceil.
Dáta sú zoskupené podľa stĺpca le, ktorý obsahuje hornú hodnotu bucketu. Naopak spodná hodnota má stĺpec gt a je jedno, či sa pri zoskupení použije jedna, či druhá.
Vizualizácia počtu požiadaviek je logaritmická (dvojkový logaritmus nameranej hodnoty). K aktuálnej hodnote je pripočítaná hodnota 1, aby boli zobrazené aj jednotlivé požiadavky. Týmto spôsobom budú dobre rozpoznateľné aj tie požiadavky, ktorých je síce málo, ale trvajú napríklad veľmi dlho.
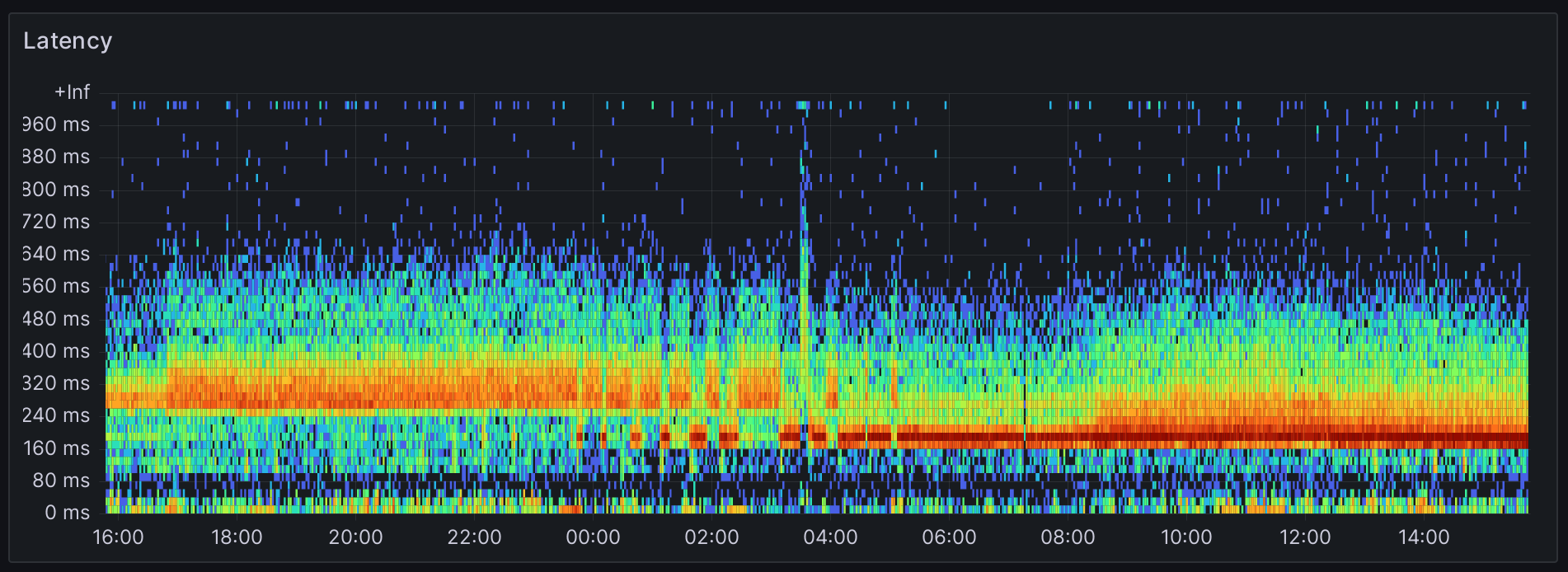
Konfigurácia dashboardu je aspoň z môjho pohľadu nateraz finálna. Nakoniec prikladám screenshot kompletného dashboardu so všetkými jeho kurlinkami.